Writing a Python Library for the Atto Node API

I recently wrote a Python wrapper for the Atto Node API (GitHub), and I wanted to share my journey—from figuring out how to convert Atto addresses, to designing around Python’s async model, to publishing a usable API wrapper. Hopefully, this helps someone else who's either interested in Atto or wants to see what writing an API wrapper looks like from a beginner's perspective.
🚀 Why I Started
At the time, there were no Python API wrappers available for Atto. The only libraries available targeted JS/WASM, used only by the wallet, and Kotlin.
I wanted to play around with the API, but to do that, I needed to convert an Atto public key (a base32-encoded string) into a hex string, which the API expects. I wrote some code for this in Python, the journey of which I'll expand on below.
Using curl and copying and pasting addresses to make requests was getting
tedious, so I switched to using Python for that too.
At some point, I realized: “I’m already halfway to an API wrapper. Why not
finish it?”. There weren’t that many endpoints, so it seemed like a manageable
project.
As a student, this felt like a fun way to procrastinate from real work™.
🧠 Reverse Engineering the Address Format
I started by figuring out how the Atto address (e.g., atto://...) becomes a
public key that the API understands.
After poking around the Atto org on GitHub, I found this bit of Kotlin:
private fun String.fromAddress(): ByteArray {
return Base32.decode(this.substring(SCHEMA.length).uppercase() + "===")
}
This seemed straightforward. So, I implemented the decoding part in Python:
import base64
# Should not include the schema (atto://)
address = '<address>'
address_bytes = base64.b32decode(address.upper() + '===')
for byte in address_bytes:
print(format(byte, '02X'), end='')
But my curl requests were failing. Comparing my output with a network request from the actual wallet, I noticed extra bytes in my output.
With Rotilho (the creator of Atto)'s help, we tracked it down:
- The first byte is the version.
- The last 5 bytes are a checksum.
These are only needed for human-readable addresses, and the API doesn't want them. So I just sliced them off:
for byte in address_bytes[1:-5]:
# ^^^^^^
print(format(byte, '02X'), end='')
Clean hex output, and the API was happy.
🧪 Curl Fatigue and First Scripts
I initially used curl for quick API checks, but copying and pasting addresses
and typing out endpoints repeatedly got old, fast. So I wrote a script in
Python to make it easier.
Eventually, I wanted something cleaner and more structured—a proper API wrapper.
🧰 Building the Library
The Basics
I started with a simple AttoNode class and used Python’s built-in requests
module for non-streaming endpoints, like:
GET /accounts/{publicKey}
That part was smooth.
The Async Problem
Streaming endpoints, however, were a challenge. Using requests.get() blocks
the thread—bad news for real-time updates.
In search of the part that was blocking (and with hopes of writing a
non-blocking version of requests.get()), I dug into the source code of
requests.get(), which led me to some internal methods, which led me to
urllib3. This quickly turned into a rabbit hole.
So I looked for an alternative. That’s when ChatGPT introduced me to asynchronous programming:
import httpx
import asyncio
async def stream_lines(url):
async with httpx.AsyncClient() as client:
async with client.stream("GET", url) as response:
async for line in response.aiter_lines():
print(f"Got line: {line}")
asyncio.run(stream_lines("http://example.com/stream"))
This was my first time diving into async io. Naturally, I got confused. A lot.
🧵 Learning Async the Hard Way
I turned to Real Python’s async guide—an excellent but long read. It gave me a rough understanding.
Then I discovered the Trio project and Nathaniel J. Smith’s blog post: "Notes on structured concurrency (or: Go statement considered harmful)" — I would highly recommend it.
I decided to build my async version using trio. But aiohttp, the popular
async HTTP library shown in the Real Python article, doesn’t support Trio
natively. So I found httpx instead, which does.
🧩 Sync vs Async: The Dilemma
At this point, I had a tough decision:
- Write a synchronous library → beginner-friendly, but can’t handle streaming.
- Write an async library → handles streaming, but alienates newcomers.
So I asked ChatGPT what other API wrappers do. To minimize hallucinations, I approached it methodically:
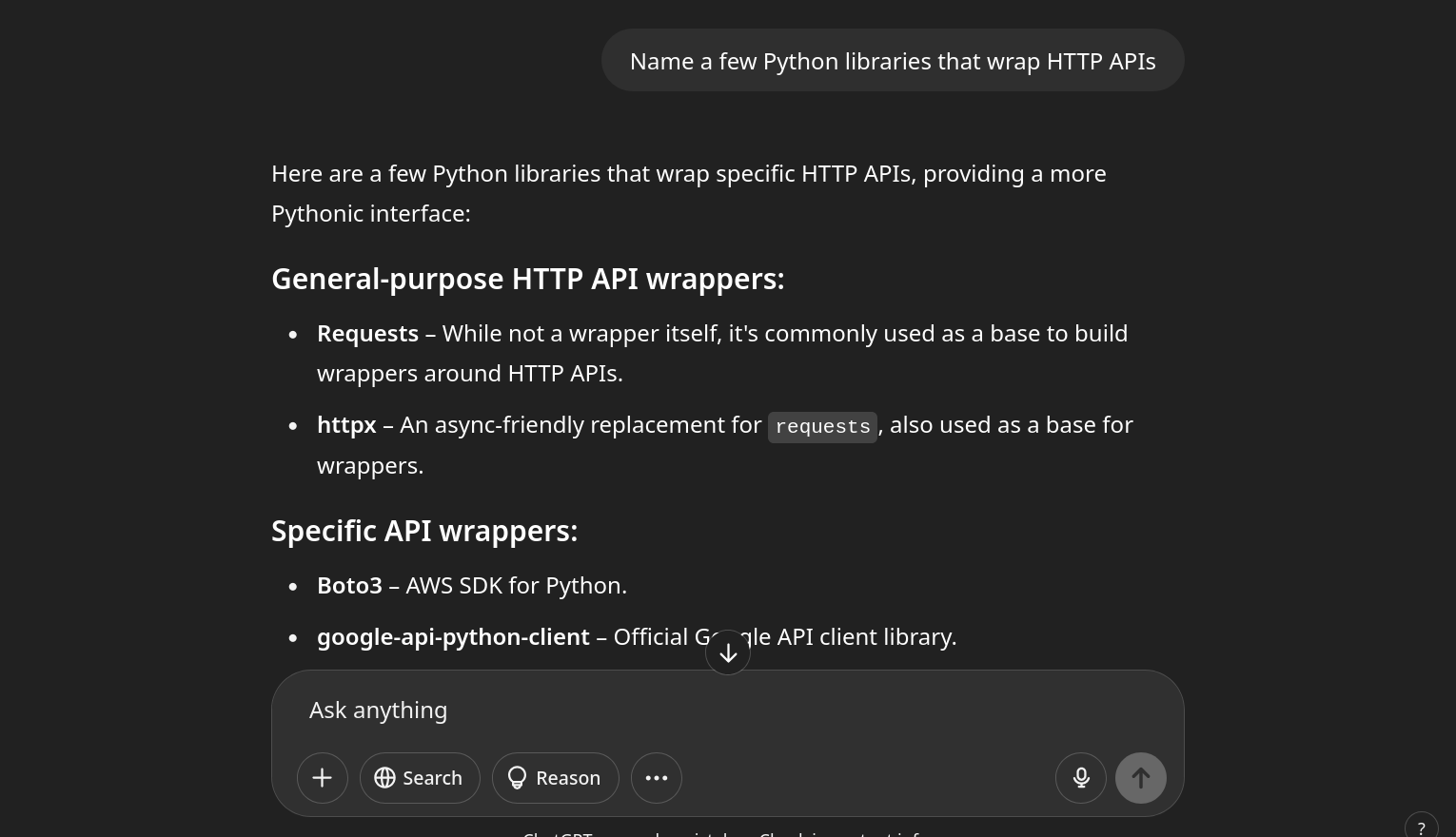
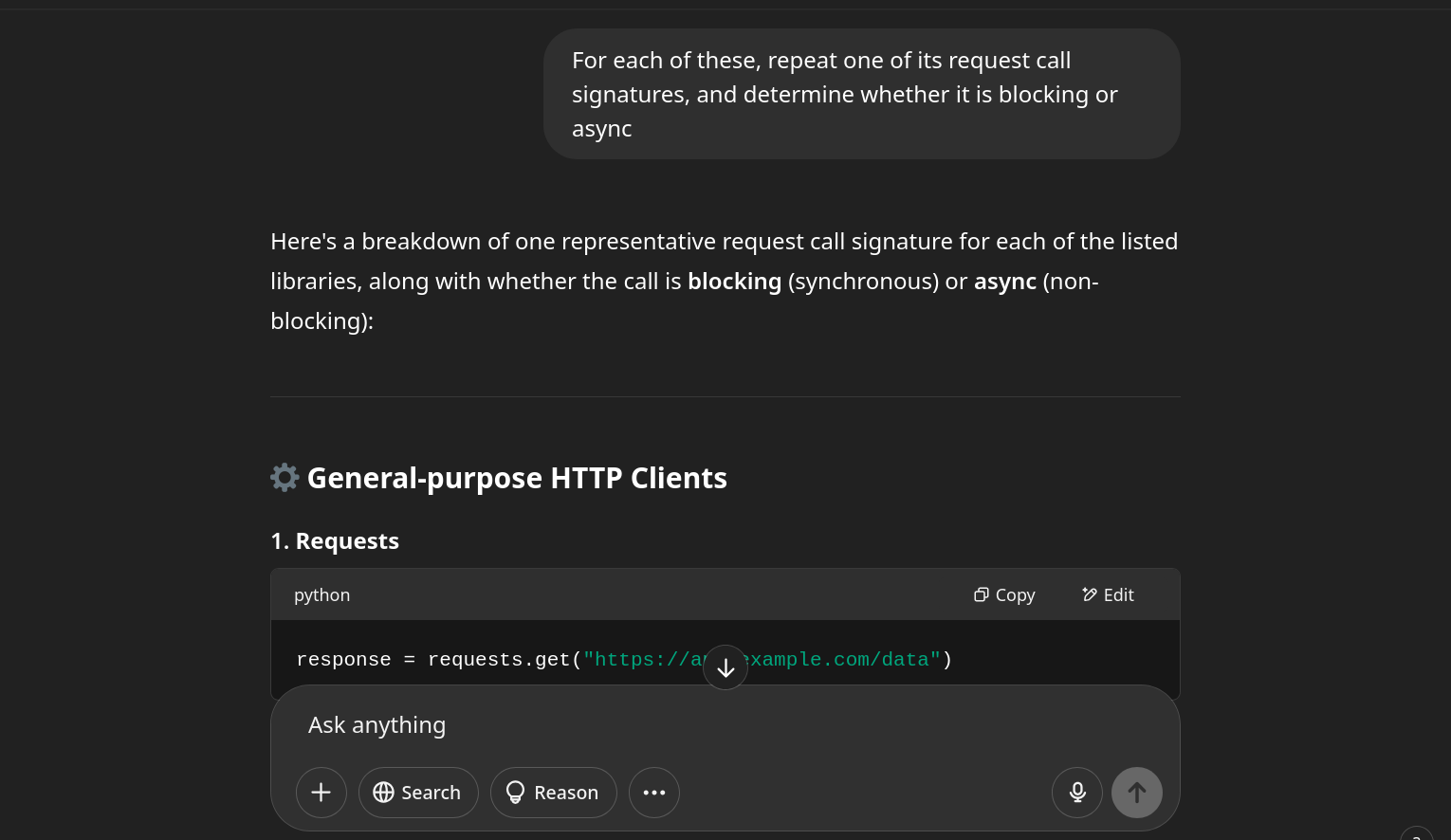
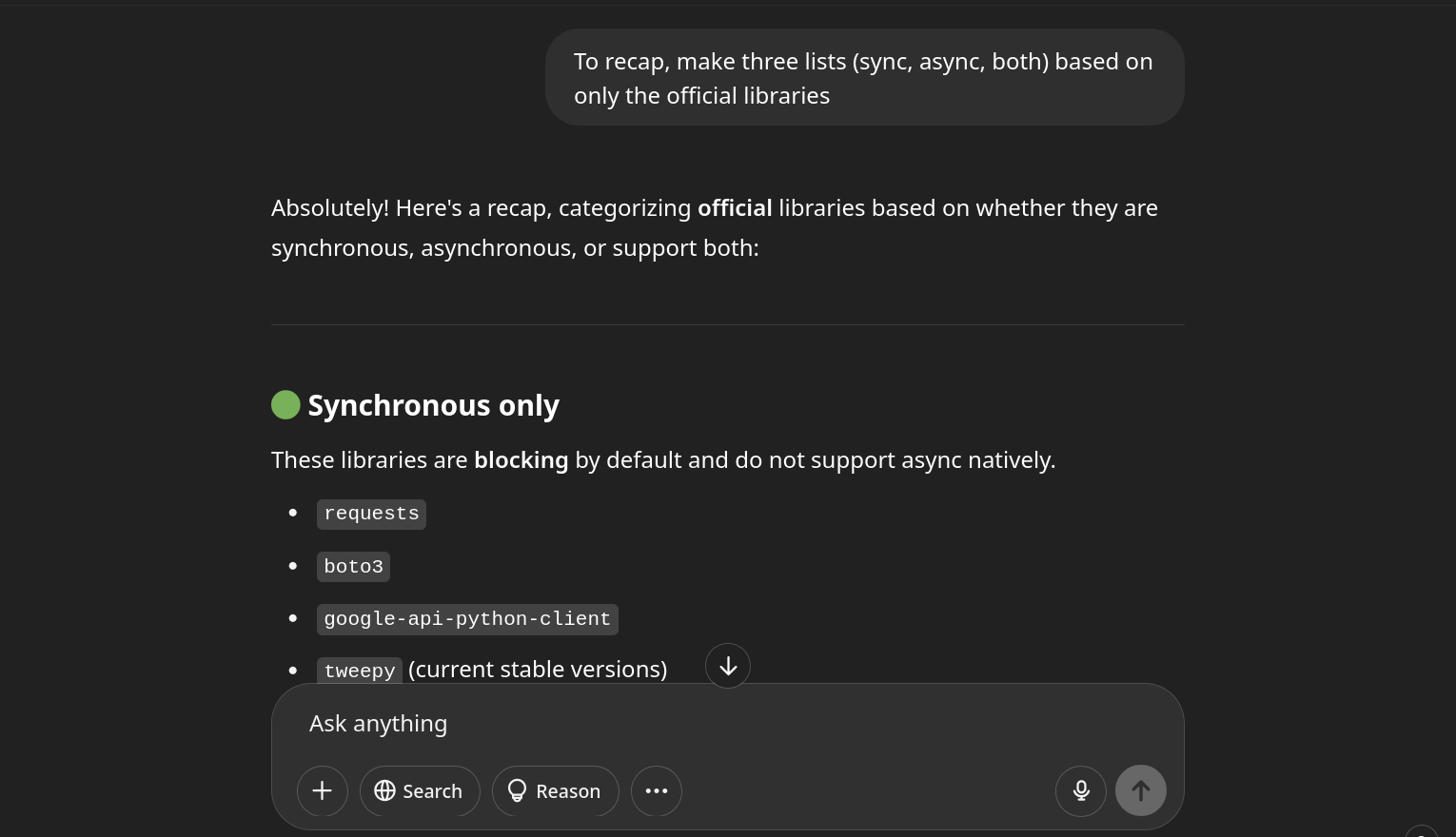
From that research, I concluded that supporting both is the best option. Separate clients—one sync, one async.
🧾 Summary
This little side project took me through:
- Reverse engineering some simple decoding logic
- Navigating Kotlin, Python, and Javascript
- Discovering the world of asynchronous programming
- Learning Trio and choosing the right HTTP client
- Making design choices while writing a Python library
And in the end, I’ve got a clean, usable API wrapper—and a lot more knowledge.
And, as a bonus, I got to write documentation (using
Sphinx), publish it to
Read the Docs, and publish a package to
PyPI for everyone to install using
pip install atto.py. All that in roughly half a day using
PyScaffold.
If you’re interested in testing it out, I’d love to hear from you! You can find the repo here. I'm not currently accepting pull requests, though, because there's still a lot of work left that I have planned out in my head.
Disclaimer: This is a guest post contributed by a community member. The views and opinions expressed are those of the author and do not necessarily reflect those of the Atto or its maintainers. While we appreciate and encourage community contributions, we cannot guarantee the accuracy or completeness of third-party content.